








Databases have been a staple topic on every digital business. Thus organizing the tables and fields is necessary. The concept of Relational Database was born way back in 1969 when Edgar F. Codd, a researcher from IBM, wrote the process of outlining a database. From there, the this concept has spread on every computing-involved business and task.
According to Wikipedia,
A relational database is a database that has a collection of tables of data items, all of which is formally described and organized according to the relational models.
This means that using the relational model, each table arrangement must be identify a column or group of columns to distinctly identify each row also called as primary key.
Using a foreign key, it can be used to establish a connection between each row in the table and a row from another table.
To properly organize a database, it involves database normalization. This is the process of organizing the tables and fields of this kind of database to minimize redundancy of information.
That being said, using definitions and terms alone won’t make you understand this topic. In this article, you’re going to learn how you can properly structure this specific database. You are going to look on two fictional tables and start working on it.
The Data
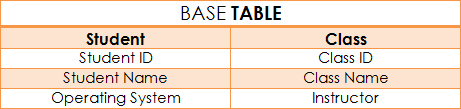
For the data, below, the base table includes two tables: Student table and Class table.
This database maintains data about the Student’s information and Class information.
Each student will have a unique Student ID (which may consist of letters and numbers) but may have similar name, operating system, class and instructor. One instructor may teach more than one class.
The Student table will have the following fields:
- Student ID
- Student Name
- Operating System
The Class table will have the following fields:
- Class ID
- Class Name
- Instructor
Now to expand the data, below presented are the Student table and Class table.


Identifying the data objects and relationships between tables
Now using the given data, you need to identify the data objects and relationship that need to be maintained in the database.
Looking at the Student and Class tables, you can conclude that the data objects are Student and Class. The relationship is that one student can have one or more classes.
Identifying Relevant Attributes: Primary Key and Foreign Key
Now that data object and relationships between the two tables have been defined, specify the relevant attributes between the two.
If you are going to check the two tables, you need to find the unique column for each table. Notice that you have only 1 row on each table that contains some unique data.
For the Student table, you have the Student ID while, in the Class table, you have the Class ID. These two rows are called the Primary Key.
The primary key of a relational table uniquely identifies each record in the table.

Next, for the relationship, you need to determine its attribute(s) and identify its Foreign key.
The foreign key matches the primary key column of another table. The foreign key is used to cross-reference tables. In this case, you will use Enrollment as our new field to connect the two foreign keys:
- Enrollment (Student ID) attribute is a foreign key referencing the Student (Student ID) attribute from the Student table.
- Enrollment (Class ID) attribute is a foreign key referencing the Class (Class ID) key attribute from the Class table.
Using Relational Tables
Now that you have identified your primary key and foreign key, you need to create a relational table to represent the data objects and relationships with their attributes and constraints.
See table below:

The foreign key Student ID in the Enrollment table references the primary key Student ID in the Student table.
The foreign key Class ID in the Enrollment table references the primary key Class ID in the Class table.
In the table above, you created a new row called Enrollment ID to relate both Student ID and Class ID, which is also define the foreign keys.
Conclusion
That’s really it! That is how you to create a database of this kind. When creating such databases, you can define the domain of possible values in a data column and further constraints that may apply to that data value.
It also requires the normalization process to remove the redundant data and connect all of the tables into one table.
In this article, you learned something about the concept of such database and how to design one; so, how do you implement one?
If using Relational Database Management Systems (RDBMS) software is your answer, you are correct! But I won’t be discussing the process in this article.
I will create another article for that soon. Hope you learned something from this article and let me know about your thoughts on the comment section.























No Comments